Реализация параллельного выполнения запросов на T-SQL
| ПРИМЕЧАНИЕ Стоит сразу оговориться, речь не пойдет о реализации многопоточности в ее классическом понимании, т.е. о создании потоков, объектов синхронизации и прочих сопутствующих сущностей. Речь пойдет об имитации многопоточного выполнения t-sql кода в распределенной системе (на нескольких linked серверах) и синхронизации этого кода средствами, предоставляемого sql server job agent. |
Продемонстрируем это на диаграмме:
- Классический вариант. Последовательный вызов процедур.

Рисунок 1.
- Второй вариант. Параллельный запуск процедур из тела основной процедуры или запроса.
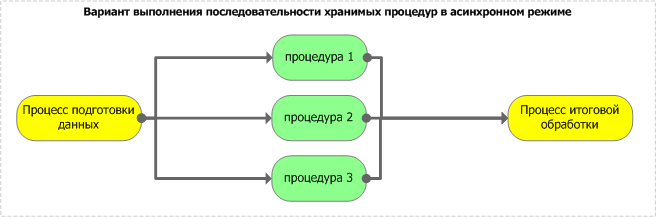
Рисунок 2.
Применять описываемый подход стоит в следующих случаях:
- Есть несколько подряд идущих процессов обработки данных, последовательность выполнения которых не важна, и которые логически не зависят друг от друга.
- Выполнение процессов происходит на разных серверах или на одном сервере, но важна синхронизация их завершения (т.е. в ситуациях, когда итоговому процессу требуются результаты выполнения нескольких процессов – см. диаграмму 2).
- Параллельно выполняемые запросы являются достаточно независимыми в части обновления, удаления или вставки данных. В противном случае ни о каком выигрыше в производительности не может быть и речи. Напротив, результатом будет только падение производительности из-за ожидания процессами друг друга на защелках (“pageiolatch”) или блокировках (“lock”).
- Для большей отдачи от данного подхода рекомендуется, чтобы каждый из процессов использовал таблицы, располагающиеся в разных файловых группах, идеально – когда еще и на отдельных дисковых устройствах, хотя это и не обязательно.
- Процессы пытаются добавлять, удалять, обновлять данные в одной таблице.
- Есть дефицит ресурсов памяти.
- Слабая дисковая подсистема
Предварительная настройка
Для демонстрации параллельного выполнения запросов необходимо иметь два экземпляра SQL Server. Между ними должны быть корректно настроены связи (“linked server”). Назовем их linked_server_01 для первого сервера, linked_server_02 – для второго. Для корректной работы приложенных примеров необходимо также, чтобы у каждого из серверов была настроена связь, ссылающаяся на самого себя. Важно правильно настроить security context для каждого из linked server-ов – доступ должен осуществляться от имени пользователя, имеющего набор прав для управления job’ами – в простейшем случае sysadmin. Для простоты можно установить security context от имени sa. В настройках server options каждого из linked server необходимо установить свойства RPC и RPC Out.Более того, на каждом из серверов должен быть запущен SQL Server Job Agent.
К данной статье прилагается два набора SQL-скриптов. Первый из них реализует всю функциональность, описываемую в этой статье. Он содержит весь набор хранимых процедур, который потребуется для реализации описываемого механизма. Необходимо создать отдельную базу Tools, в которой следует выполнить данные запросы, создав, таким образом, все процедуры. Второй прилагаемый набор скриптов демонстрирует пример использования данного механизма. Вы можете создать базу Article_Sample_Data на первом сервере и выполнить на ней второй прилагаемый скрипт.
Проверить правильность настройки можно, запустив на каждом из серверов системную процедуру sp_helpserver.
Вы должны получить следующий результат:

Рисунок 3.
Для корректной работы скриптов на linked server-ах также необходимо убедиться в том, что на каждом из серверов работает служба Microsoft Distributed Transaction Coordinator (о проблемах с ее настройкой читайте дальше в разделе “ Описание проблем при настройке DTC и возможные их решения”). MS DTC используется MS SQL Server для поддержки распределенных транзакций (а здесь будет именно такой случай). Проверить работоспособность msdtc можно, запустив на каждом из MSSQL серверов следующий скрипт:
begin transaction execute linked_server_01.article_sample_data.dbo.sp_executesql N'select getdate()' execute linked_server_02.article_sample_data.dbo.sp_executesql N'select getdate()' commit |
Описание реализации
Как уже упоминалось, никаких встроенных средств для реализации параллельного исполнения запросов в t-sql нет, но есть SQL Server Job Agent, отвечающий за выполнение запросов по расписанию. Так что параллельного исполнения T-SQL можно добиться через создание заданий (“job”) для агента. Именно этот подход и рассматривается в этой статье. Стоит отметить, что он дает возможность параллельного выполнения запросов не только на одном сервере, но и на нескольких.Кроме того, данный подход предоставляет возможность ограничения количества одновременно выполняющихся процессов. Если количество асинхронных запросов в пуле превышает установленный максимум, то запросы дожидаются своей очереди и обрабатываются по мере высвобождения ресурсов сервера. Такая необходимость возникает, если сервер ограничен в ресурсах памяти.
В самом общем случае такая система состоит из центрального управляющего сервера, на котором располагается пул запросов, и произвольного количества управляемых серверов, которым запросы передаются на исполнение (в нашем случае управляющим сервером будет linked_server_01).
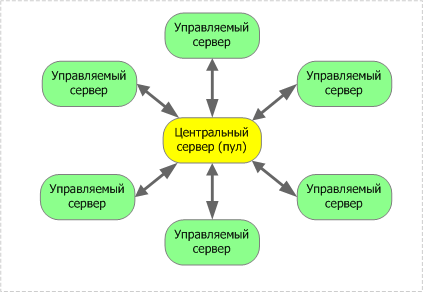
Рисунок 4.
В простейшем случае, когда требуется выполнение нескольких задач в параллельном режиме, никаких дополнительных настроек или установки linked server на себя не требуется.
Целиком весь SQL-код, реализующий управление очередью заданий, можно увидеть в коде хранимых процедур прилагаемой базы данных Tools (см. Предварительная настройка).
Этот код можно изучить и детально обсудить с авторами – здесь же мы приводим только описание его «интерфейсной» части, доступной пользователю.
Использование данного механизма состоит из двух этапов – подготовка списка запросов и собственно его обработка.
Пул запросов должен содержаться в таблице со следующей структурой:
create table [TaskList] ( linked_server nvarchar(100) DEFAULT (''), job_name nvarchar(100) DEFAULT (''), toDelete bit, checkRun bit, job_step_name nvarchar(200), job_step_sql_script nvarchar(4000), job_step_database nvarchar(200), status bit NULL DEFAULT (1), job_started bit NULL DEFAULT (0), job_prepare_for_synchronize bit NULL DEFAULT (0), job_executed bit NULL DEFAULT (0), id int identity(1,1) NOT NULL ) |
- job_name – имя задания, которое будет создано для выполнения запроса. Это имя может помочь вам ориентироваться среди заданий, чтобы определить время или успешность его выполнения.
- toDelete – параметр, определяющий, следует ли удалять задание после его завершения.
- linked_server – имя сервера, на котором должен быть выполнен запрос.
- job_step_database – имя базы данных, к которой адресуется запрос.
- job_step_name – имя шага (“step”), который будет создан в задании (в данной реализации в каждом задании создается только один шаг).
- job_step_sql_script – это тот самый запрос (T-SQL), который должен быть выполнен в асинхронном режиме.
В качестве простейшего примера приведем формирование пула запросов:
insert into [TaskList] ( linked_server, job_name, toDelete, job_step_name, job_step_sql_script, job_step_database) select '', 'demo_UpdateCustomers', 1, 'step 01', N'update Customers set Region = ‘’N/A’’ where Region is null', 'Northwind' ---------------------------------------------------------------------------- insert into [TasksList] ( linked_server, job_name, toDelete, job_step_name, job_step_sql_script, job_step_database) select '', 'demo_RemoveOrders', 1, 'step 01', N'delete from Orders where ShipCity is null', 'Northwind' ---------------------------------------------------------------------------- insert into [TasksList] ( linked_server, job_name, toDelete, job_step_name, job_step_sql_script, job_step_database) select '', 'update_Employees', 1, 'step 01', N'update Employees set Region = ‘’London’’ where Country = ‘’UK’’', 'Northwind' |
update Customers set Region = ’N/A’ where Region is null delete from Orders where ShipCity is null update Employees set Region = ‘London’ where Country = ‘UK’ |
Для запуска этих запросов в параллельном режиме используется процедура support_StartJobsAndWaitFor (Tools.dbo.support_StartJobsAndWaitFor), которая реализует всю логику управления пулом, запуска запросов и обработки результатов их работы.
Основные параметры процедуры:
CREATE PROCEDURE [dbo].[support_StartJobsAndWaitFor] @temporary_table_name nvarchar(100), @SimultaneousJobsMaxCount tinyint = 10 |
Примером вызова может быть следующий запрос:
execute support_StartJobsAndWaitFor @temporary_table_name = 'Northwind.dbo.[TasksList]' |

Рисунок 5.
Рассмотрим более сложный пример: допустим, требуется произвести вышеупомянутые t-sql-операции на двух настроенных серверах параллельно. Более того, допустим, что одна из выполняемых операций приведет к ошибке:
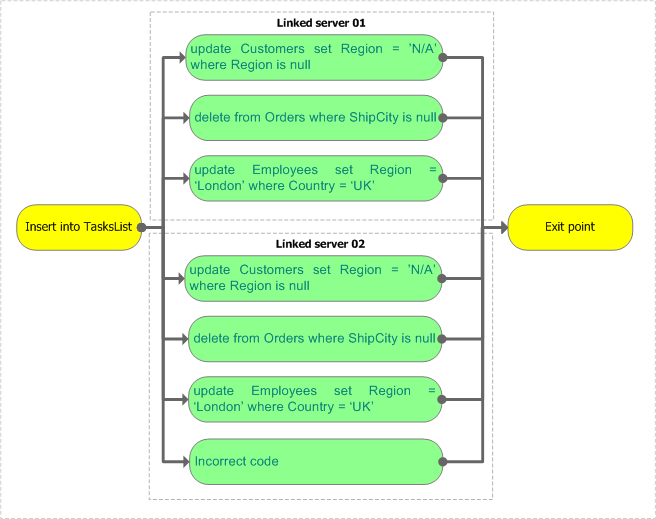
Рисунок 6.
Запустим ее на выполнение, предварительно открыв Job Activity Monitor на серверах. Мы должны увидеть следующее:
На linked_server_01 были созданы и выполнены следующие задания:

Рисунок 7.

Рисунок 8.

Рисунок 9.
-- ------------------------------------------------------------------------ -- 1.2 Формируем список job-ов -- ------------------------------------------------------------------------ insert into [TaskList] ( linked_server, job_name, toDelete, checkRun, job_step_name, job_step_sql_script, job_step_database) select '', 'demo_UpdateCustomers', 0, 1, 'step 01', N'update Customers set Region = ''N/A'' where Region is null', 'Northwind' -- ------------------------------------------------------------------------ insert into [TaskList] ( linked_server, job_name, toDelete, checkRun, job_step_name, job_step_sql_script, job_step_database) select '', 'demo_RemoveOrders', 0, 1, 'step 01', N'delete from Orders where ShipCity is null', 'Northwind' -- ------------------------------------------------------------------------ insert into [TaskList] ( linked_server, job_name, toDelete, checkRun, job_step_name, job_step_sql_script, job_step_database) select '', 'update_Employees', 0, 1, 'step 01', N'update Employees set Region = ''London'' where Country = ''UK''', 'Northwind' -- ------------------------------------------------------------------------ -- !!! -- Регистрация задачи на удаленном linked_server insert into [TaskList] ( linked_server, job_name, toDelete, checkRun, job_step_name, job_step_sql_script, job_step_database) select 'linked_server_02', 'demo_UpdateCustomers', 0, 1, 'step 01', N'update Customers set Region = ''N/A'' where Region is null', 'Northwind' insert into [TaskList] ( linked_server, job_name, toDelete, checkRun, job_step_name, job_step_sql_script, job_step_database) select 'linked_server_02', 'demo_RemoveOrders', 0, 1, 'step 01', N'delete from Orders where ShipCity is null', 'Northwind' insert into [TaskList] ( linked_server, job_name, toDelete, checkRun, job_step_name, job_step_sql_script, job_step_database) select 'linked_server_02', 'update_Employees', 0, 1, 'step 01', N'update Employees set Region = ''London'' where Country = ''UK''', 'Northwind' -- Регистрация задачи на удаленном linked_server -- с заведомо некоректным t-sql кодом insert into [TaskList] ( linked_server, job_name, toDelete, checkRun, job_step_name, job_step_sql_script, job_step_database) select 'linked_server_02', 'Incorrect democode', 0, 1, 'step 01', N'incorrect t-sql code', 'Northwind' -- ------------------------------------------------------------------------ -- 1.3 Запускаем подготовленные job-ы и ждем их завершения -- ------------------------------------------------------------------------ -- executing and wait for execute Tools.dbo.support_StartJobsAndWaitFor @temporary_table_name = 'linked_server_01.Article_Sample_Data.dbo.[TaskList]', -- Максимальное количество одновременно работающих @SimultaneousJobsMaxCount = 03, -- timeOut между итерациями проверки статуса job-ов @delay_time = '00:00:03', @delete_jobs = 0 |
Комментарии к коду примера
Как указывалось выше, процедура Tools.dbo.support_StartJobsAndWaitFor выполняет всю работу по управлению пулом. В качестве ее параметров указывается количество одновременно запущенных задач и время между периодическими опросами работающих процессов (параметр @delay_time – что-то вроде Thread.Sleep (), на самом деле waitfor delay). Параметр @temporary_table_name – для данного примера мы указываем полный путь к таблице описания пула запросов, видимой как с linked_server_01, так и с linked_server_02 – поэтому здесь и уделено особое внимание описанию правильной настройки межсерверных связей на обоих серверах в самом начале статьи.Если вы посмотрите свойства любого созданного задания, то увидите не тот скрипт, который поместили в таблицу [TaskList], а немного видоизмененный, например, такой:
declare @sql_script nvarchar(4000) set @sql_script = ' update TaskList set job_started = 1 where linked_server = ''linked_server_02'' and job_name = ''demo_UpdateCustomers'' ' execute linked_server_01.Article_Sample_Data.dbo.sp_executesql @sql_script update Customers set Region = 'N/A' where Region is null |
Описание проблем при настройке DTC и возможные их решения
Сообщение об ошибке:| ПРЕДУПРЕЖДЕНИЕ MSDTC on server ' |
Необходимо запустить службу msdtc. Для этого в командной строке нужно запустить dcomcnfg (Component services), в списке computers найти текущий, из контекстного меню вызвать start MS DTC.
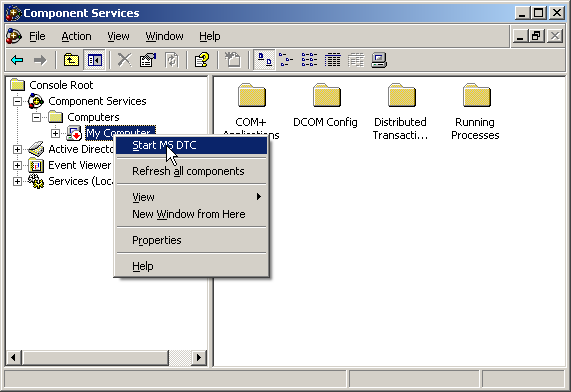
Рисунок 10.
- Remote Procedure Call (RPC) Locator.
- Remote Procedure Call (RPC).
- Должен быть запущен COM+ System Application – вот с запуском этой службы могут возникнуть проблемы. После старта может быть выдано сообщение о том, что сервис не может стартовать. В таком случае необходимо просмотреть event log – если он содержит сообщение такого плана:
Event Type: Error
Event Source: COM+
Event Category: (98)
Event ID: 4822
Date: 4/22/2007
Time: 1:08:54 PM
User: N/A
Computer: DUSHES-MOBILE
Description:
A condition has occurred that indicates this COM+ application is in an unstable state or is not functioning correctly. Assertion Failure: SUCCEEDED(hr)
Server Application ID: {02D4B3F1-FD88-11D1-960D-00805FC79235}
Server Application Instance ID:
{88E823F3-8336-4499-82BF-5670D772B9F7}
Server Application Name: System Application
The serious nature of this error has caused the process to terminate.
Error Code = 0x8000ffff : Catastrophic failure
COM+ Services Internals Information:
File: d:\qxp_slp\com\com1x\src\comsvcs\tracker\trksvr\trksvrimpl.cpp, Line: 3000
Comsvcs.dll file version: ENU 2001.12.4414.258 shp |
1. Click Start, click Run, type secpol.msc, and then click OK. 2. In the left pane, expand Local Policies, and then click User Rights Assignment. 3. In the right pane, double-click Impersonate a client after authentication. 4. Click Add User or Group. 5. Type service in the Enter the object names to select box, and then click OK two times. 6. Restart the computer. |
2. В левой панели окна консоли развернуть ветку «Local Policies» и затем выбрать «User Rights Assignment».
3. В правой панели консоли двойным щелчком мыши вызвать диалог «Impersonate a client after authentication».
4. Щелкнуть по «Add User or Group».
5. Ввести в текстовое поле «the Enter the object names to select box» значение «service» и затем дважды нажать «OК», закрыв все открытые диалоги консоли «Local Security Settings».
6. Перезапустить компьютер.
Если же и после этого сервис COM+ System Application не запускается, тогда последнее, что можно сделать, это перерегистрировать следующие com-серверы:
regsvr32 comsvcs.dll regsvr32 ole32.dll regsvr32 oleaut32.dll |
| ПРЕДУПРЕЖДЕНИЕ The operation could not be performed because the OLE DB provider 'SQLOLEDB' was unable to begin a distributed transaction. [SQLSTATE 42000] (Error 7391) OLE DB error trace [OLE/DB Provider 'SQLOLEDB' ITransactionJoin::JoinTransaction returned 0x8004d00a]. [SQLSTATE 01000] (Error 7300) [SQLSTATE 01000] (Error 7312). The step failed. |
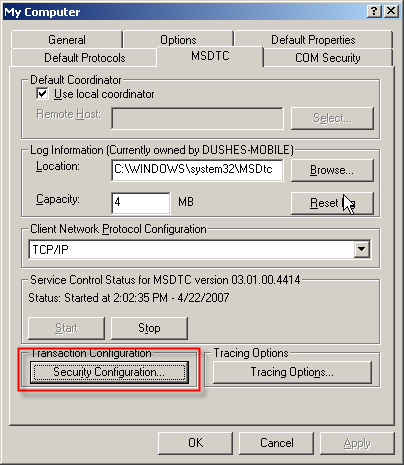

Рисунок 11.
Master.dbo.sysProcesses как альтернатива Activity monitor, недокументированные возможности
| ПРЕДУПРЕЖДЕНИЕ Нижеприведенный код будет работать на MSSQL 2000 Server только при условии установки Service Pack 3 и выше. Код является рабочим также и для MS SQL 2005. |
Оказывается, все это можно увидеть и получить с помощью master.dbo.sysprocesses.
Для следующей демонстрации стоит открыть две сессии, необязательно на тех базах данных, скрипты для создания которых идут вместе с данной статьей. В первой сессии выполним следующее:
select @@spid waitfor delay '00:10' |
Во второй сессии выполним следующее:
select spid, cpu, stmt_start, stmt_end, sql_handle, * from master..sysprocesses processes (nolock) where dbid = db_id() order by processes.cpu desc |

Рисунок 12.
Пока в первой сессии выполняется скрипт waitfor, во второй запустим следующее (после предыдущего select):
Declare @sql_handle varbinary(20), @sql_text nvarchar(4000), @stmt_start int, @stmt_end int select @sql_handle = sql_handle, @stmt_start = stmt_start, @stmt_end = stmt_end from master..sysprocesses (nolock) where spid = 57 select * from ::fn_get_sql(@sql_handle) select @sql_text = [text] from ::fn_get_sql(@sql_handle) select @sql_text as all_executed_code, substring(@sql_text, @stmt_start/ 2, case when @stmt_end > 0 then @stmt_end /2 else len(@sql_text) end) as current_executed_code |
Здесь использована недокументированная функция ::fn_get_sql(varbinary sql handle), которая по полученному sql_handle сессии возвращает весь выполняющийся t-sql код (собственно, это то, что мы можем увидеть в activity monitor, щелкнув по интересующей нас сессии). Результат выполнения:
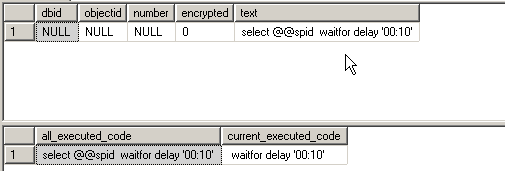
Рисунок 13.
В коде:
select @sql_text as all_executed_code, substring( @sql_text, @stmt_start/ 2, case when @stmt_end > 0 then @stmt_end /2 else len(@sql_text) end) as current_executed_code |
Динамические скрипты, вызов на linked_server
На форумах часто приходится видеть примерно такие вопросы: «Как получить данные из таблицы, имя которой зависит от ряда причин?». Ответом, как правило, является совет использовать динамические скрипты (хотя, в зависимости от задачи, возникают и варианты использования разветвления кода через if). В своей практике мы тоже часто используем динамические скрипты, например, в таких случаях, когда условие отбора записей where неизвестно и зависит от определенной логики, для описанного случая с именем таблицы, и прочих. Но отдельно нужно выделить те случаи, когда скрипт необходимо запустить на другом сервере, имя которого на момент написания скрипта неизвестно или может меняться в зависимости от каких-либо условий.| СОВЕТ Для запуска динамических скриптов один из авторов использует вызов системной процедуры sp_executesql, у которой, по сравнению с инструкцией execute(N’string’), синтаксис гораздо богаче и позволяет параметризовать скрипт. Это удобнее для восприятия (хотя и имеется ограничение на максимальную длину скрипта в 4000 символов, в отличие от execute(N’string’), позволяющей произвести конкатенацию нескольких строк максимальной длиной по 4000 символов – речь идет об nvarchar type). Поясним на примере: -- таблица, используемая для теста динамического скрипта if ( isnull(object_id('tempdb..#test'), 0) > 0 ) drop table #test create table #test ( id int identity, [value] int ) insert into #test ([value]) select 1 union select 2 union select 3 union select 4 union select 5 declare @sql_script nvarchar(4000), @where_value int -- значение для отбора записей по полю [value] set @where_value = 3 -- использование dynamic script через execute (N'string') set @sql_script = N' select * from #test where [value] >= ' + cast(@where_value as nvarchar(10)) execute(@sql_script) -- использование dynamic script через sp_executesql set @sql_script = N' select * from #test where [value] >= @value ' execute sp_executesql @sql_script, N'@value int', @value = @where_value Если в случае использования execute(N’string’) мы сформировали строку, где для условия where было подставлено определенное значение посредством приведения числового значения переменной @where_value к типу данных nvarchar(), то во втором случае мы явно указали объявление переменной @value, указали ее тип, и уже затем использовали ее в логике самого запроса, проинициализировав при вызове dynamic script переменную @value значением @where_value. Возможно, данный пример не является показательным, но во втором случае мы имеем явное указание параметров запроса, видим их использование в самом запросе, видим их инициализацию, аналогично объявлению хранимой процедуры и ее вызову. |
declare @destination_linked_server nvarchar(100), @source_linked_server nvarchar(100), @execute_script nvarchar(4000), @sql_script nvarchar(4000) set @destination_linked_server = 'linked_server_02' set @source_linked_server = 'linked_server_01' -- 1. -- на указанном сервере нужно просто запустить хранимую процедуру ... -- для данного случая подразумеваем, что наша БД указана, -- путь это будет TempDB, а вызвана будет просто -- системная процедура (хотя можно было подставить имя своей БД -- и имя конкретной процедуры) set @execute_script = 'execute ' + @destination_linked_server + '.TempDB.dbo.sp_helpserver' execute sp_executesql @execute_script -- если проанализировать профайлером, то такой вызов -- ничем не отличается от прямого вызова -- execute linked_server_02.TempDB.dbo.sp_helpserver -- 2. -- Во втором случае рассматривается ситуация, когда имя linked–сервера -- неизвестно на момент вызова скрипта, более того, -- сам скрипт должен работать на linked–сервере -- (скажем, затянуть данные с другого сервера, может потребоваться -- для реализации метода pull для передачи данных между серверами; -- о разнице между pull и push говорится в разделе -- "Как вернуть данные из temporary table чужой сессии") set @sql_script = ' select * from ' + @source_linked_server + '.master.dbo.sysservers ' set @execute_script = 'execute ' + @destination_linked_server + '.TempDB.dbo.sp_executesql @outer_sql_script' execute sp_executesql @execute_script, N'@outer_sql_script nvarchar(4000)', @outer_sql_script = @sql_script |

Рисунок 14.
Во втором случае имеется текст запроса, который должен быть вызван на стороне указанного сервера. Т.е. мы имеем ситуацию, когда один динамический скрипт вызывает другой.
Схематично это можно изобразить так:
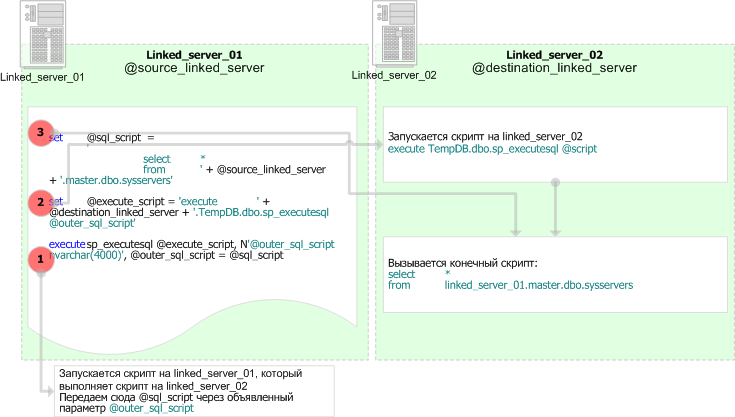
Рисунок 15.
set @execute_script = 'execute ' + @destination_linked_server + '.TempDB.dbo.sp_executesql @outer_sql_script' |
execute sp_executesql @execute_script, N'@outer_sql_script nvarchar(4000)', @outer_sql_script = @sql_script |
Если проанализировать работу такого кода профайлером, можно убедиться, что запуск скрипта
select * from linked_server_01.master.dbo.sysservers |
Проверка linked_server на loopback
Иногда возникает необходимость проверить, ссылается linked_server сам на себя или нет (является ли он loopback-сервером) – хотя бы для того, чтобы избежать проблем, описанных в BOL (только при использовании на серверах MS SQL 2000, проблема loopback linked servers решена на MS SQL 2005).| ПРЕДУПРЕЖДЕНИЕ Loopback-серверы нельзя использовать в распределенной транзакции. Loopback linked servers cannot be used in a distributed transaction. Attempting a distributed query against a loopback linked server from within a distributed transaction causes an error: |
Описание реализации
Собственно, алгоритм достаточно прост. Ищем указанный сервер в списке master.dbo.sysservers, анализируем DataSource на соответствие хосту текущего сервера (host_name()) или IP-адресу (IP-адреса текущего сервера получаем, запустив через xp_cmdShell команду ipconfig) – если есть совпадение, то считаем что linked_server ссылается сам на себя. Собственно, данный алгоритм и реализован в коде прилагаемой хранимой процедуры Tools.dbo.support_CheckLinkedServer.Для демонстрации запустим следующий скрипт на ранее настроенном сервере, где размещена база данных Tools:
declare @isRemote bit declare @isExists bit -- loopback server execute linked_server_01.Tools.dbo.[support_CheckLinkedServer] @linked_server_name = 'linked_server_01', @isRemote = @isRemote output, @isExists = @isExists output select @isRemote, @isExists -- not loopback execute linked_server_01.Tools.dbo.[support_CheckLinkedServer] @linked_server_name = 'linked_server_02', @isRemote = @isRemote output, @isExists = @isExists output select @isRemote, @isExists -- linked server not exists execute linked_server_01.Tools.dbo.[support_CheckLinkedServer] @linked_server_name = 'not_exists_linked_server', @isRemote = @isRemote output, @isExists = @isExists output select @isRemote, @isExists |
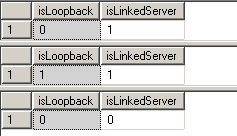
Рисунок 16.
Как вернуть данные из temporary table чужой сессии (только mssql2000)
| ПРЕДУПРЕЖДЕНИЕ Все нижеописанное относится только к MSSQL 2000, для MSSQL 2005 описанный подход работать не будет. |
Итак, для демонстрации сделаем следующее – в той сессии, где мы собираемся создать тестовую временную таблицу, запустим следующий код:
select @@spid create table #test_table (id int identity, test varchar(100)) insert into #test_table select 'string_01' union all select 'string_02' select * from #test_table select object_id('tempdb..#test_table') |
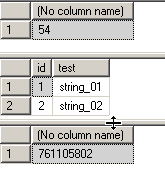
Рисунок 17.
select * from tempdb..sysobjects(nolock) where id = 761105802 |

Рисунок 18.
select * from tempdb..[#test_table_________________________________________________________________________________________________________000000000048] |
| ПРЕДУПРЕЖДЕНИЕ Database name 'tempdb' ignored, referencing object in tempdb. Msg 208, Level 16, State 0, Line 1 Invalid object name '#test_table_________________________________________________________________________________________________________000000000048'. |
declare @table_name varchar(100) set @table_name = 'temp_' + cast(newid() as varchar(36)) update tempdb..sysobjects set name = @table_name where id = 761105802 |
| ПРЕДУПРЕЖДЕНИЕ Msg 259, Level 16, State 2, Line 3 Ad hoc updates to system catalogs are not enabled. The system administrator must reconfigure SQL Server to allow this. |
execute sp_configure 'allow updates', 1 reconfigure with override execute sp_configure |

Рисунок 19.
Запустим скрипт:
declare @table_name varchar(100) set @table_name = 'temp_' + cast(newid() as varchar(36)) update tempdb..sysobjects set name = @table_name where id = 761105802 select * from tempdb..sysobjects(nolock) where id = 761105802 |
select * from tempdb..[temp_8A04E767-299B-48DE-A4A8-B17F70BCCEF5] |
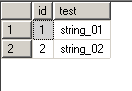
Рисунок 20.
| ПРИМЕЧАНИЕ В начале данной темы я упомянул, что мне приходится использовать такой подход для реализации передачи данных между linked-серверами. Объясню суть возникшей передо мной в свое время проблемы и выбранное для нее решение. Проблема: есть множество процедур, производящих определенные предварительные расчеты статистики в нашей системе. Есть необходимость пересылать полученные данные на другой сервер, который, собственно, не отвечает за предварительные расчеты, но отвечает за отображение данной статистики, т.е. на указанном сервере находятся таблицы-приемники конечных результатов. Объем полученных данных, как правило, большой. Существует два варианта передачи – условно их можно назвать pull и push. При первом варианте (pull) данные затягиваются с сервера-источника на сервер-приемник данных скриптом, который выполняется на самом сервере-приемнике данных. То есть если бы у нас сервером-источником данных являлся linked_server_01, а сервером-приемником данных - linked_server_02, то данный вариант выглядел бы на t-sql так: -- скрипт выполняется на Linked_server_02: Insert into destination_table select * from linked_server_01.catalog.owner.source_table В случае push – данные не забираются с сервера-источника данных, а заталкиваются на сервер-приемник данных, то есть: -- скрипт выполняется на Linked_server_01: Insert into linked_server_02.catalog.owner.destination_table select * from source_table На первый взгляд, оба варианта равноценны, но на самом деле разница очень и очень существенная. Можно сразу сказать, что первый вариант на порядки производительнее второго, так как процесс переноса данных во втором случае происходит по сути своей построково, в чем легко убедиться путем профилирования запросов описанных типов. О разнице в использовании обоих подходов можно подробнее узнать из статьи Михаила Смирнова по следующей ссылке: http://www.sql.ru/subscribe/2007/354.shtml#20 Полученные в результате выполнения хранимых процедур (по расчету статистики на сервере-источнике) данные сохранялись в постоянных таблицах. Затем эти данные забирались посредством хранимой процедуры, запускаемой на сервере-приемнике, которая собственно и выполняла сохранение данных методом pull, т.е. данные именно забирались с сервера-источника. Соответственно, для каждого вида статистики имелась отдельная постоянная таблица на локальном сервере (источнике) и отдельная хранимая процедура на удаленном (приемнике). Лично я противник дублирования кода и создания всякого рода дополнительных объектов в БД, так как это приводит к дополнительной нагрузке на сопровождение таких объектов – а именно, в моем случае, поддержка соответствия структуры таких таблиц как процедурам передачи данных, так и процедурам расчета. Решение: Именно поэтому я решил отказаться от использования постоянных таблиц и перешел на использование единой процедуры передачи данных, которой передаю object_id() временной таблицы с результатами, полученными с сервера-источника данных. Процедура передачи данных описанным выше методом обновляет имя временной таблицы в tempdb сервера-источника данных и осуществляет собственно выборку данных. Не скажу, что на все 100% уверен в правильности выбора такого решения, но за полгода использования проблем не возникало. Однако при переходе на MS SQL Server 2005 возникнет проблема, так как описанное выше решение работать уже не будет. – прим. Андрея Смирнова |
Возврат курсора из динамического скрипта
Следует иметь в виду, что для корректной работы из динамического скрипта можно вернуть только открытый курсор, что и демонстрируется на примере:declare @sql_script nvarchar(4000), @outer_cursor cursor set @sql_script = ' set @return_cursor = cursor local forward_only for select ''string_01'' union all select ''string_02'' union all select ''string_03'' open @return_cursor ' execute sp_executesql @sql_script, N'@return_cursor cursor output', @return_cursor = @outer_cursor output fetch next from @outer_cursor while (@@fetch_status = 0) fetch next from @outer_cursor close @outer_cursor deallocate @outer_cursor |





